Artificial Intelligence, Machine Learning & Data Science: What’s the Difference?

If there’s one thing that unites Artificial Intelligence, Machine Learning, and Data Science, it’s Venn diagrams. It’s a sure sign we’ve reached the peak of a technology’s hype cycle when the popular articles about it stop complaining about buzzwords and start complaining about all the articles complaining about buzzwords. That seems to be the case for artificial intelligence (AI), machine learning (ML), and data science: all three have been characterized as empty buzzwords, world-shaking disruptors, and almost everything in between.
Although they’re not empty buzzwords, the impact of AI, ML, and data science has certainly been overblown, no doubt in part due to screenwriters and dystopian science fiction novelists.
The issue isn’t that they’re not revolutionary, it’s just that revolutions of this kind tend to move more slowly than one might expect. That’s because the fourth industrial revolution, as it’s sometimes called, is really more of an evolution.
The pace of change notwithstanding, it’s important for businesses to get clear on these three related concepts—artificial intelligence, machine learning, and data science—at least before Skynet sticks us all in the Matrix or Facebook figures out how to control its users utterly via their personal data. (Just kidding.)
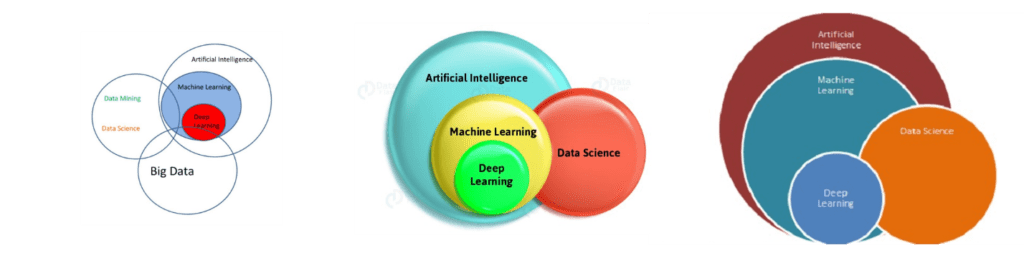
At Acerta, we’re using artificial intelligence (in the form of machine learning) and data science to help automakers detect the earliest indicators of future product failures, so we’re well versed in these ideas. You can’t really talk about AI, ML, or data science on its own without invoking the other two, so some confusion around their delineations is understandable. So, for clarity’s sake, let’s take a look at what sets these three items apart.
What is Artificial Intelligence (AI)?
 There’s no shortage of definitions for AI, but one of the simplest ways to describe it is the implementation of quasi-cognitive capacities in computers. As Alan Turning pointed out over half a century ago, talking about AI in terms of machines “thinking” tends to be unproductive. Still, even with a more modest definition, AI hasn’t turned out how anyone expected.
There’s no shortage of definitions for AI, but one of the simplest ways to describe it is the implementation of quasi-cognitive capacities in computers. As Alan Turning pointed out over half a century ago, talking about AI in terms of machines “thinking” tends to be unproductive. Still, even with a more modest definition, AI hasn’t turned out how anyone expected.
Some things that we thought would be difficult if not impossible for machines to do turned out to be quite easy (e.g., playing chess) while capacities that human children take for granted have turned out to be much more difficult to implement in AI (e.g., natural language processing or object recognition).
The popular notion of AI, also known as general artificial intelligence, is still largely the stuff of science fiction. Narrow AI, on the other hand, has seen considerable progress in recent years. That’s because narrow AI is about focusing on specific, discrete tasks, such as classifying x-rays or managing supply chains.
As much as AI is framed as a disruptive innovation—potentially the biggest one ever—we’ve already gone through several periods of reducing interest and funding, known as “AI winters,” which result from broad setbacks in AI development, such as the collapse of the Lisp machine market or the publication of the Lighthill report. The latest wave of AI enthusiasm came about around 2011 with the success of various machine learning projects, such as IBM’s Watson beating human players at Jeopardy or the Google Brain team’s neural network learning to recognize cats based on unlabeled YouTube videos.
What is Machine Learning (ML)?
While the two are often conflated, machine learning is a subset of AI that involves using algorithms or statistical models to perform a specific task without explicit instructions. Hence, an ML algorithm or model has a “goal” but since it isn’t told how to achieve that end, it must rely on statistical inference and pattern recognition.
In contrast to the more programmatic approaches to AI, machine learning is more akin to the way organisms interact with their environments.
For example, army ants will self-assemble into bridges without any explicit instructions regarding how or when to do so; crossing a gap is their goal, and a bridge made of ant bodies is the most efficient solution.
Since ML algorithms are built around finding patterns, they’re heavily dependent on data. This explains why machine learning applications saw a significant uptick in the 2010s, when data acquisition, storage, and processing became sufficiently inexpensive to enable a host of new applications.
Today, machine learning examples can be found in facial recognition programs, autonomous driving projects, and natural-language user interfaces like Amazon’s Alexa and Apple’s Siri. At Acerta, our data scientists are using machine learning to help automakers find the earliest indicators of future product failures.
What is Data Science?
 The newest and arguable most “buzzwordy” of our three concepts, data science is a multi-disciplinary field that includes statistics, machine learning, and data analytics. Although some have suggested that ‘data scientist’ is just “a fancy term for a statistician,” there are important differences between statistics and data science.
The newest and arguable most “buzzwordy” of our three concepts, data science is a multi-disciplinary field that includes statistics, machine learning, and data analytics. Although some have suggested that ‘data scientist’ is just “a fancy term for a statistician,” there are important differences between statistics and data science.
Statistics is about extracting as much information as possible from small amounts of data.
Consequently, the most common tools in statistics are designed to defend against drawing faulty inferences, such as the t-test, the F-test, or regression analysis. In contrast, data science is about dealing with data volumes that are large enough to require different methods, such as machine learning. That’s because the risk of making a faulty inference goes down with larger datasets, but it also hides in new places and hence requires new tools to mitigate.
What’s the Difference?
Regardless of your industry, the odds are good that you’ll encounter artificial intelligence, machine learning, or data science during the course of your career, probably sooner rather than later. When that happens, it’s important to keep these concepts clear in your mind, because the unfortunate fact is that many companies do use them solely as buzzwords for self-promotion. A company that is experienced in AI, ML, and data science will be able to demonstrate that knowledge with proven results.
Author Profile
 Greta Cutulenco is the CEO and co-founder of Acerta Analytics Solutions. She has worked at major OEMs and Tier 1s, including Bombardier and Magna, on system testing, monitoring, and analysis; and at AECL (nuclear) on testing processes. Prior to that, Greta worked for 3 years as a software engineer and web developer. Greta’s M.Sc research at the University of Waterloo focused on automatic analysis of data for testing and anomaly detection. For more information, visit us at acerta.ai or follow us on Twitter or LinkedIn.
Greta Cutulenco is the CEO and co-founder of Acerta Analytics Solutions. She has worked at major OEMs and Tier 1s, including Bombardier and Magna, on system testing, monitoring, and analysis; and at AECL (nuclear) on testing processes. Prior to that, Greta worked for 3 years as a software engineer and web developer. Greta’s M.Sc research at the University of Waterloo focused on automatic analysis of data for testing and anomaly detection. For more information, visit us at acerta.ai or follow us on Twitter or LinkedIn.
(Images courtesy of AI Trends, Altron Karabina, Data Flair, David Perez/Innaxis Foundation and Research Institute, Gill Press/What’s the Big Data, Jeremy Karnowski/Insight Data Science Fellows Program, mc.ai, Oleksii Kharkovyna/Towards Data Science and Vijay Kotu & Bla Deshpande.)